经过开篇对Java运行机制及相关环境搭建,本篇主要讨论Java程序开发的基础知识点,我简单的梳理一下。在讲解数据类型之前,我顺便提及一下Java注释:单行注释、多行注释以及文档注释,这里重点强调文档注释。通常单行注释独占一行并用"//"来开头,多行注释会占据多行并用/*...*/来表示。
/* HelloWorld是每一个Java学习者的起点, 需要好好掌握*/public class HelloWorld { public static void main(String[] args) { // 输出Hello World! System.out.println("Hello World!"); }} 那什么叫文档注释呢?简单的说,就是利用javadoc将源代码的文档注释生成一份API文档,供使用者查询和参考。JDK API的在线文档查询:,从文档界面不难看出分成三大区:包列表区(左上方)、类列表区(左下方)、详细说明区(右侧)。点击左侧"类列表区"中的类,右侧将显示该类对应的构造函数、属性、方法等详细信息。接下来,我们利用javadoc来生成一份API文档,需要说明的是,javadoc只处理以public或protected修饰的类、接口、方法、属性、构造器和内部类之前的文档注释而忽略其他地方的文档注释,如果开发者希望给使用者提供private成员的文档,则需要加入-private选项。文档注释用/**...*/来表示。javadoc的语法如下:
javadoc -d [API文档存放目录] -windowtitle [API文档浏览器标题] -doctitle [概述页面标题] -header [页面页眉] ... Java源文件/包 (可利用javadoc -help查询全部选项)
如源代码中包含中文,则需要设置-locale, -encoding, -charset如下:
javadoc -d [API文档存放目录] -windowtitle [API文档浏览器标题] -doctitle [概述页面标题] -header [页面页眉] -encoding utf-8 -charset utf-8 -locale zh_CN ... Java源文件/包 (可利用javadoc -help查询全部选项)
同时,为了更详细说明类、方法等成员的文档信息,经常添加以下javadoc标记(如@author、@version、@param、@return等)到这些成员上加以说明。
package miracle;/*** Description:* 此程序主要测试Javadoc指令来生成文档注释* 程序名:TestJavadoc.java* 编写日期:2012-08-22* @author Miracle, He miracle@sina.com* @version 1.0*/public class TestJavadoc { /** * 测试属性 */ protected String name; /** * 主方法,程序入口 * @param args 输入参数列表 */ public static void main(String[] args) { System.out.println("Hello, Miracle!"); }} package miracleHe;/*** Description:* 此程序主要测试Javadoc指令来生成文档注释* 程序名:TestJavadocTag.java* 编写日期:2012-08-22* @author Miracle, He miracle@sina.com* @version 1.0*/public class TestJavadocTag { /** * 此方法用来打招呼 * @param name 打招呼的名称 * @return 返回打招呼的字符串 */ private String hello(String name) { return name + ",你好!"; }} 我们这里添加了两个包miracle和miracleHe(目的为生成概述),执行以下命令将输出API文档。
javadoc -d apidoc -windowtitle "Generate Javadoc" -doctitle "Learning HelloWorld Class by Javadoc" -header "Javadoc Test" -charset "utf-8" -encoding "utf-8" Test*.java
默认情况下不会提取@author、@version等信息,如需提取则需要添加。
javadoc -d apidoc -windowtitle "Generate Javadoc" -doctitle "Learning HelloWorld Class by Javadoc" -header "Javadoc Test"-charset "utf-8" -encoding "utf-8" -author -version Test*.java
Java是强类型语言,也就是变量或表达式在编译时就已经明确其类型,即先声明后使用。数据类型分为: 基本类型(Primitive Type)和引用类型(Reference Type)。其组织关系如下:基本类型包含整数类型(byte、short、int、long)、字符类型(char)、浮点类型(float、double)和布尔类型(true、false);引用类型包含字符串(String)、数组、类、接口和空类型(null)。先从整数类型谈起,如果一个较小的整数(在byte或short的范围之内)赋值给byte或short时,系统会自动转化为对应的类型;如果一个巨大的整数(超出int的范围),系统则不会自动当做long来进行处理,需要添加后缀L来进行标识,即使这个整数在int的范围之内声明的long类型变量不添加L仍然当做是int。
public class TestInteger { public static void main(String[] args) { byte b = 56; //系统会自动转化为byte //long big = 999999999999; //出错,系统不会当作long来处理 long big2 = 41433333313243133L; //使用L强制为long类型 }} 整数除了十进制来表示外,还可以使用八进制(0开头)以及十六进制(0x开头,A~F代表10~15)来进行表示。
int octalValue = 013;int hexValue = 0x2F;
虽然字符型被单独处理,但其实它就是一种整数(0~65535之间的无符号整数),字符通常可以使用''(如'A')、转义字符('\n'、'\r')和Unicode('\uXXXX',前256个字符与ASCII码一致)来表示。如果将0~65535之间的整数赋给char变量将直接将int转化为char类型。
public class TestChar { public static void main(String[] args) { //定义字符型 char a = 'a'; char enter = '\r'; char ch = '\u24af'; System.out.println(ch);//输出? char yu = '宇'; int yuValue = yu; System.out.println(yuValue);//23431 char c = 97; System.out.println(c);//a }} 但请注意,字符串虽然是由字符组成(可看作字符数组),但字符串是引用类型。接下来,我们讨论一下浮点数。浮点数分为单精度浮点数(float)和双精度浮点数(double)。其中float占4个字节,第一位是符号位,接下来8位是指数位,最后23位是尾数,必须要添加后缀F;double占8个字节,第一位是符号位,接下来11位是指数位,最后52位是尾数,是默认类型,可以不添加后缀D来标识。浮点数可用十进制(如5.12,.512)和科学计数法(5.12E2)来表示。特别需要注意的是:浮点数还包含三个特殊的值,正无穷大(POSITIVE_INFINITY,通过正数除以0得到)、负无穷大(NEGATIVE_INFINITY,通过负数除以0得到)和非数(NaN,通过0.0除以0.0或对负数开方得到)。所有正无穷大值都相等,所有负无穷大值相等,非数不与任何数相等(包含NaN本身也不相等)。
public class TestFloat { public static void main(String[] args) { float f = 5.12F; double zero = 0.0; float p = Float.POSITIVE_INFINITY; double n = Double.NEGATIVE_INFINITY; System.out.println(p==n);//false System.out.println(f/zero);//Infinity System.out.println(f/zero==p);//true System.out.println(0.0/zero==Double.NaN);//false System.out.println(6.0/0==8.2/0);//true System.out.println(1/0);//抛出异常 }} 另外提一句,bool类型只能为true或false,不能用0或非0来表示,其他基本类型都不能转化为bool类型,如果bool类型与字符串相连,将直接转化为字符串。
接下来,我们讨论一下数据类型转换相关知识。数据类型转换分为自动转换和强制转换,自动转换的关系如下图:
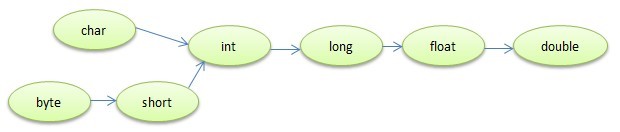
箭头左边的类型可以自动转化为右边的类型。此外,当基本类型与字符串进行连接时,基本类型会自动转换为字符串。反之,将字符串转化为基本类型则调用xxx.pareseXxx方法(如Integer.parseInt("12"))。
public class AutoConversion { public static void main(String[] args) { int a = 6; float f = a; System.out.println(f);//6.0 byte b = 9; //char c = b;//出错,byte不能自动转化为char double d = b; System.out.println(d);//9.0 //基本类型与字符串进行转化 String s = 5.3F + ""; System.out.println(s);//5.3 System.out.println(3 + 4 + "Hello!");//7Hello! System.out.println("Hello!" + 3 + 4);//Hello!34 }} 反之,如果想把箭头右边的类型转换为左边的类型,就需要强制类型转换,这样做可能导致数据溢出或精度丢失。因此在进行强制类型转换时需格外小心。
public class ForceConversion { public static void main(String[] args) { int i = 234; byte b = (byte)i; System.out.println(b);//-22 double d = 3.56; int n = (int)d; System.out.println(n);//3 }} 可能大家会问234咋转换为byte就变成了-22了呢?我们都知道,byte的范围是-128~127,显示超出了表示的范围,234的二进制表示为00..0011101010,转换后截取后8位之后变成11101010,而第一位是符号位(这里是个负数),而负数在计算机中以补码形式存在,需要转换为原码(补码减1成反码再按位取反,符号位不变,因此:11101010-->11101001-->10010110)。
在进行表达式计算时,数据类型会发生自动提升:如所有byte、short和char将自动提升为int类型,表达式的数据类型将提升为最高等级操作数的数据类型。对于整数相除时,即使不能除尽也要舍弃小数部分,对于字符串与数字或字符相加时,此时应该从左自右进行运算,以判断是否为字符串连接还是加法运算。
public class AutoPremotion { public static void main(String[] args) { short s = 5; //s = s - 2;//出错,表达式被提升为int byte b = 10; char c = 'a'; double d = .12; System.out.println(b + c + d);//表达式被提升为double System.out.println(23 / 3);//7 System.out.println(b + c + "Hello!");//107Hello! System.out.println("Hello!" + b + c);//Hello!10a }} 在讲解流程控制之前,我在这里补充一下平常容易出错的知识点。我们来看以下程序:
public class CompareString { public static void main(String[] args) { String a = new String("Miracle"); String b = new String("Miracle"); System.out.println(a == b);//false,因此a与b指向不同的实例(尽管内容一致) String c = "Miracle"; String d = "Miracle"; System.out.println(c == d);//true,此处由于字符串缓存机制,比较的仅仅是两者的内容 }} 另外,对于短路运算符(如||)与不短路运算符(如|)的区别: ||先计算左边的操作数,如果为true将不再继续计算,而|不管左边结果如何都会计算之后的操作数。
public class TestLogicOperator { public static void main(String[] args) { int a = 5; int b = 10; if(a > 4 || b++ > 10) { System.out.println("a=" + a + ",b=" + b);//a=5,b=10 } if(a > 4 | b++ > 10) { System.out.println("a=" + a + ",b=" + b);//a=5,b=11 } }} 接下来,进入流程控制的讲解,任何编程语言(Java也不例外)的流程控制结构包含:顺序结构和分支结构(if、if...else、if...else if...else、switch)和循环结构(while、do...while、for、foreach)。这里不再举例说明,只是强调一点,对于分支结构if...else,尽量不要省略之后的花括号,即使只有一条语句也不能省略,其中对于非常简单的if...else结构,可以用三目运算符(if(a>b)?a:b)来替代。为了避免发生逻辑错误,应该遵守:总是优先把包含范围小的的条件放在前面处理。
public class TestIf { public static void main(String[] args) { int age = 45; if(age > 20) { System.out.println("Young"); } else if(age > 40) { System.out.println("Middle"); } else if(age > 60) { System.out.println("Old"); } }} 我们发现运行之后输出Young,明显与预期不符(应该输出Middle)。就是因为刚才提到的范围问题导致(age > 20比age > 60范围大)。我们改写一下:
public class TestIf { public static void main(String[] args) { int age = 45; if(age > 60) { System.out.println("Old"); } else if(age > 40) { System.out.println("Middle"); } else if(age > 20) { System.out.println("Young"); } }} 刚才提到if之后的花括号不能省略,对于switch...case来说,case之后的花括号尽量省略,而break不要省略(否则将贯穿多个case执行),尽量加上default,此外对于switch(expression)的表达式只能为整数,不能为字符串(这点跟其他语言不一样)。
对于循环结构,也不要省略循环体中的花括号(即使只有一句),还可以组成多层嵌套循环。可以使用break结束本层循环,进入循环之后的代码,使用continue结束本次循环,进入下一次循环,也可以使用return直接返回。但是有时还有特殊情况,就是从内层循环跳出到外层循环,需要使用Java标签(用:表示),不过通常此标签必须位于break所在循环的外层循环之前才起作用。以下程序将输出: i = 0,j = 0;i = 0,j = 1。public class TestBreak { public static void main(String[] args) { outer: for(int i = 0; i < 5; i++) { for(int j = 0; j < 2; j++) { System.out.println("i = " + i + ",j = " + j); if(j == 1) { break outer; } } } }} 此外,continue也可添加标签,表示立即结束continue所在循环,跳到标签所在位置进入下一次循环。如果将以上的break改成continue的话,将输出: i = 0, j = 0; i = 0, j = 1; i = 1, j = 0; i = 1, j = 1; i = 2, j = 0; i = 2, j = 1; i = 3, j = 0; i = 3, j = 1; i = 4, j = 0; i = 4, j = 1。最后,return直接返回整个方法,而不管方法中嵌套有多少层循环。